Here I use the small dataset nhanes included in mice package. It has 25 rows, and three out of four variables have missings.
The original NHANES data is a large national level survey, some are publicly available via R package nhanes.
library(mice)
Attaching package: 'mice'
The following object is masked from 'package:stats':
filter
The following objects are masked from 'package:base':
cbind, rbind
# load example dataset from micehead(nhanes)
age bmi hyp chl
1 1 NA NA NA
2 2 22.7 1 187
3 1 NA 1 187
4 3 NA NA NA
5 1 20.4 1 113
6 3 NA NA 184
summary(nhanes)
age bmi hyp chl
Min. :1.00 Min. :20.40 Min. :1.000 Min. :113.0
1st Qu.:1.00 1st Qu.:22.65 1st Qu.:1.000 1st Qu.:185.0
Median :2.00 Median :26.75 Median :1.000 Median :187.0
Mean :1.76 Mean :26.56 Mean :1.235 Mean :191.4
3rd Qu.:2.00 3rd Qu.:28.93 3rd Qu.:1.000 3rd Qu.:212.0
Max. :3.00 Max. :35.30 Max. :2.000 Max. :284.0
NA's :9 NA's :8 NA's :10
Examine missing pattern with md.pattern(data).
# 27 missing in total# by col: 8 for hyp, 9 for bmi, 10 for chl# by row: n missing numbersmd.pattern(nhanes)
We can also specify which imputed dataset to use as our complete data. Set index to 0 (action = 0) returns the original dataset with missing values.
Here we check which of the imputed data is being used as the completed dataset. First take a note of the row IDs (based on bmi, for example). Then we generate completed dataset.
if no action argument is set, then it returns the first imputation by default
action=0 corresponds to the original data with missing values
# check which imputed data is used for the final result, take note of row idid_missing <-which(is.na(nhanes$bmi))id_missing
[1] 1 3 4 6 10 11 12 16 21
nhanes_impr0_action0 <-complete(impr0, action =0) nhanes_impr0_action0[id_missing, ] # original data with missing bmi
age bmi hyp chl
1 1 NA NA NA
3 1 NA 1 187
4 3 NA NA NA
6 3 NA NA 184
10 2 NA NA NA
11 1 NA NA NA
12 2 NA NA NA
16 1 NA NA NA
21 1 NA NA NA
nhanes_impr0_action1 <-complete(impr0, action =1) nhanes_impr0_action1[id_missing, ] # using first imputation
with complete data, estimate a linear regression of Y (some missing) on Z (no missing), results in coefficients \(\beta\).
draw \(\beta^*\) from the posterior predictive distribution of \(\beta\) (multivariate normal with mean b and covariance matrix of b).
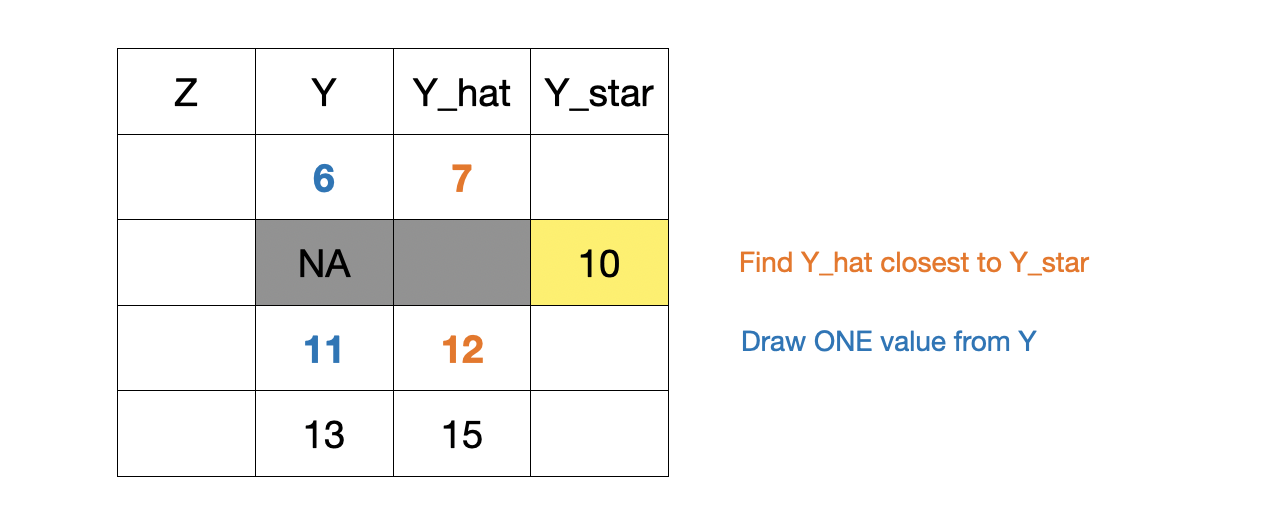
generate predicted values for \(Y_{hat}\) (complete cases) and \(Y_{star}\) (missing)
for each \(Y_{star}\), identify a few cases (7,12) whose predicted values \(Y_{hat}\) are close to the predicted \(Y_{star}\) (10 in the illustration below)
randomly draw one value from the observed \(Y\) from the doner cases (6, 11).
Assumption for PMM: distribution of missing is the same as obsereved data of the candidates that produce the closest values to the predicted value by the missing entry.
PMM is robust to transformation, less vulnerable to model misspecification.