The 2nd column (Means_pr10MJ) is the average food intake, which is same as mean in bounds data (3rd data file). It is not necessary to be in this table as it is not the per unit contribution. We will drop it in the subsequent data processing.
2. Constraints
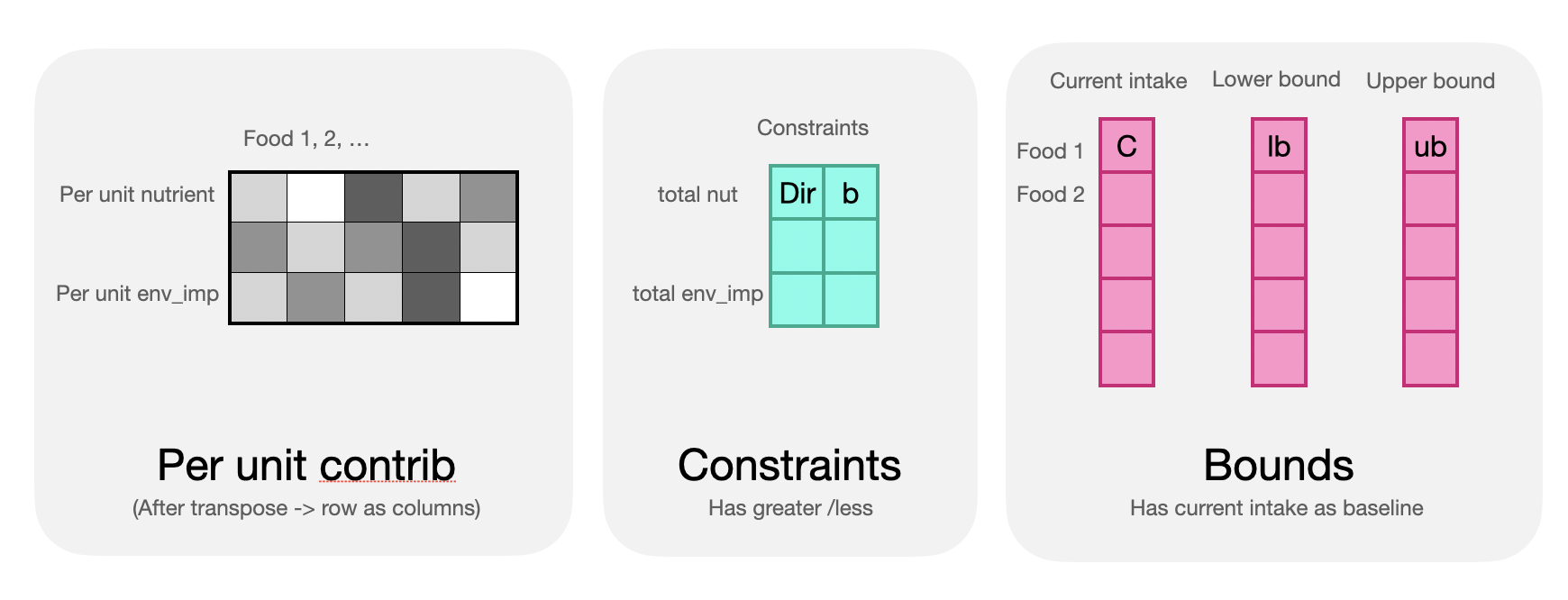
Total diet constraint limits for each outcome of interest. The names need to match the column names in contrib_per_unit (check it in the next section)
# A tibble: 6 × 3
tag_outcome Dir rhs
<chr> <chr> <dbl>
1 Energy (MJ) E 10.5
2 Protein, g, lower G 62.9
3 Protein, g, upper L 126.
4 Carbohydrates, g, lower G 283.
5 Carbohydrates, g, upper L 377.
6 Added sugar, g L 62.9
3. Bounds
Intake information on each food groups. Food names need to match the food names in contrib_per_unit.
mean: average intake based on dietary survey. Served as baseline
lower_bound, upper_bound: lower and upper permissible optimised intake.
It can be helpful to check in detail whether they match. In this case, it is because of the commas.
# check whether the values matchfood_list[, 1] == food_list[, 2]# if they do not match, can inspect in more detailsfood_list[food_list[, 1] != food_list[, 2], ]
1
this line puts all the indices where the 1st and 2nd column don’t match as the row index for food_list dataframe, and prints out all the rows corresponding to those indices
if wish to change the name, new_name = existing_name
Afterwards, compare with another table.
# extract the tags of interest from two datatags1 <-colnames(cpu)[-1]tags2 <- constraints$tag_outcome# put together for easy comparisontags_list <-cbind(tags1, tags2)# check whether the values matchtags_list[, 1] == tags_list[, 2]
# if they do not match, can inspect in more detailstags_list[tags_list[, 1] != tags_list[, 2], ]
tags1 tags2
[1,] "Vitamin A, RE µg" "Vitamin A, RE μg"
[2,] "Folate, µg" "Folate, μg"
[3,] "Vitamin B12, µg" "Vitamin B12, μg"
[4,] "Vitamin D, µg" "Vitamin D, μg"
[5,] "Iodine, µg" "Iodine, μg"
[6,] "Selenium, µg" "Selenium, μg"
[7,] "Copper, µg" "Copper, μg"
[8,] "GHGE, kg CO2-eq" "GHGE, kg COe-eq"
[9,] "FE, g P-eq" "FE, kg P-eq"
[10,] "ME, g N-eq" "ME, kg N-eq"
[11,] "TA, g SO2-eq" "TA, kg SO2-eq"
Note
Pay attention to the unmatched ones. In some cases (row 9, 10, 11) it is indeed unmatched (g vs kg); in other cases where special character is involved (such as mu), human will see the same characters but R “sees” differently due to encoding. User should decide for themselves whether they are truly different.
Data process
Objectives
Process the data so that they are in the correct format for the optimisation step
Data
Information
In Rcplex (processing required)
contrib_per_unit
Contribution per food unit
Amat
constraints
Constraint limits and directions
bvec, sense
bounds
Intake for baseline, lower and upper bounds
Qmat, cvec, lb, ub
Amat
Amat comes from contrib_per_unit (here it is called cpu). The necessary processing is to remove the first column (Food names), and transpose so that rows become columns.
The dimension for Amat is \(n_{outcomes} \times n_{foods}\), these two do not need to be equal. In this example they are equal simply because we happen to have 53 foods and 53 outcomes.
Amat <-as.matrix(t(cpu[, -c(1)])) # remove the Foodgroup, then transposedim(Amat)
[1] 53 53
bvec and sense
bvec and sense are values from the constraints data. Each pair of values should correspond to one outcome.
head(constraints)
# A tibble: 6 × 3
tag_outcome Dir rhs
<chr> <chr> <dbl>
1 Energy (MJ) E 10.5
2 Protein, g, lower G 62.9
3 Protein, g, upper L 126.
4 Carbohydrates, g, lower G 283.
5 Carbohydrates, g, upper L 377.
6 Added sugar, g L 62.9
bvec <- constraints$rhssense <- constraints$Dir #Rcplex uses E, L, and R instead of ==, <= and >=
lb, ub
lb, ub are values from bounds (here called intake).
Qmat and cvec are derived from the bound data. They are based on the current average intake (baseline).
obs <- intake$meanobssq <-1/obs^2n_food <-length(obs)# create diagonal matrix, where each diagonal value is obssqQmat <-2*as.matrix(diag(obssq, n_food, n_food)) # cveccvec <--(2/obs)
Put together as a list
For convenience, these values can be saved in an R object (a list) and used directly in the optimisation program.
d <-list(cvec = cvec, Amat = Amat, bvec = bvec, Qmat = Qmat, lb = lb, ub = ub, sense = sense)# to save: execute the following linesaveRDS(d, file ='d.RData')# to read: execute the following lined <-readRDS('d.RData')
Once this is done, you can refer to the next chapter: Run optimisation.