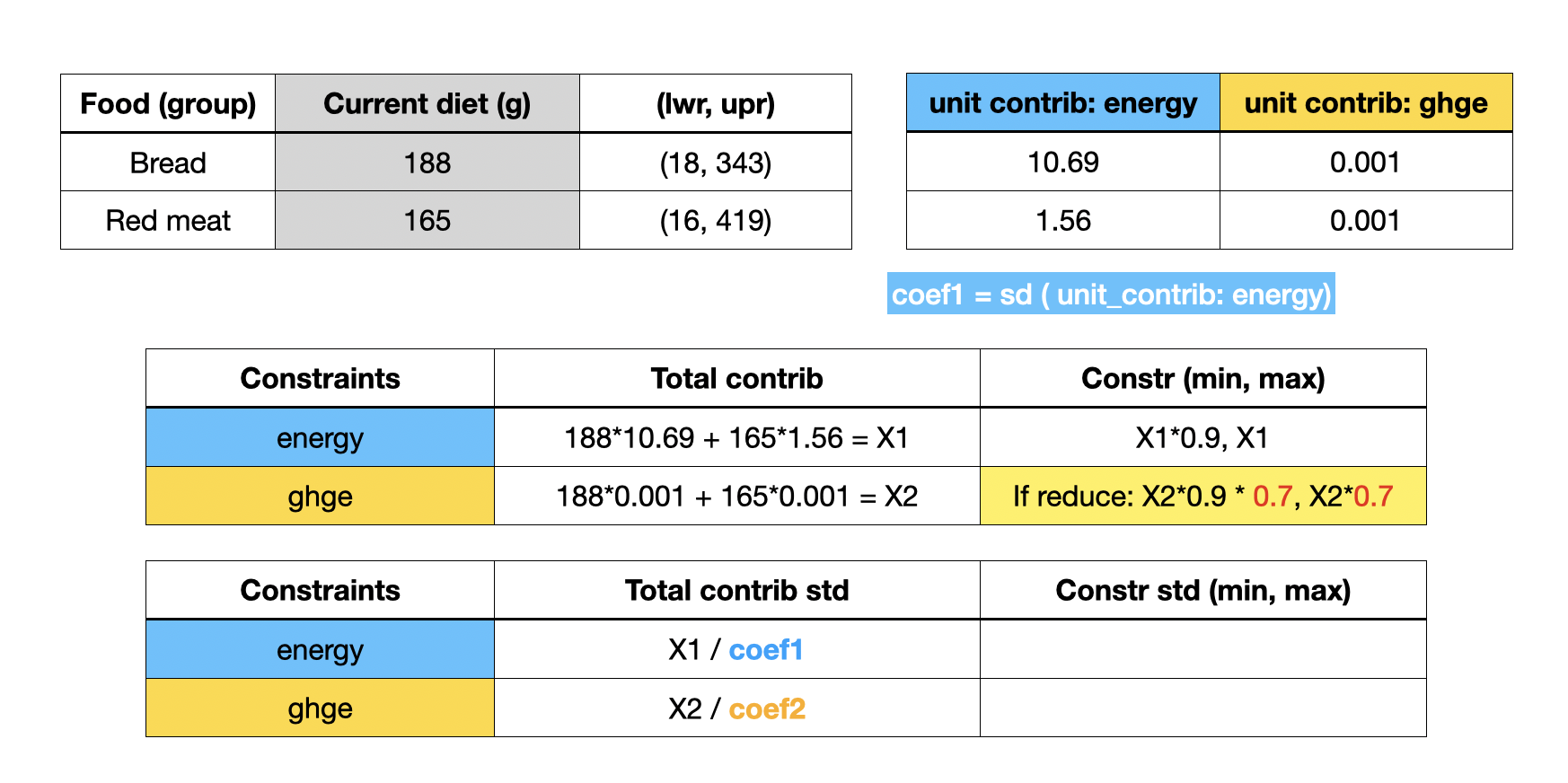
This is the current implementation of input needed for the optimization algorithm.
What does the algorithm require
The current aim of optimization is to find a set of values (‘diet’) that is similar to the current diet, yet satisfies some constraints on nutrition and environment impact.
For the objective function,
a vector of current diet (in grams), diet0. This is used to compute the deviation (sum of squares) between the new (target) and current.
For the inequality constraints (standaradized or original),
a list of constraint values, ordered by tag_outcome (e.g. energy, ghge)
inside each tag_outcome such as energy,
unit_contrib for each food: a vector of size n
lwr, upr: constraint lower and upper bound. This is after reduction.
Constraint bounds
The values of constraint bounds need to be pre-computed before entering the algorithm - that means, setting the reduction on ghge is already done.
How are constaints computed
The total contribution of a diet is a weighted sum of all food intake (diet, in gram) and contribution to this particular nutrition / environment impact outcome (tag_outcome). For instance, in total, the current diet of 188g bread and 165g red meat contributes to X1 units of energy; X2 units of ghge.
The current diet is the average for each food group among all subjects who we collected data from. The lwr, upr of the current are used to limit the search region for the new diet. In the current implementation, they are 5% and 95% quantiles from all the subject.
The inequality constraints (e.g. energy) requires two values: constr_min, constr_max. This means that the computed total contribution of the new diet need to be between these two. In the current implementation:
minimum (lower bound) is 0.9 times of the total contribution
maximum (upper bound) is the same of the total contribution
if we want to reduce ghge, then multiply a factor to the two values above.
In addition to the raw values, we also implement a standardized version for each of the tag_outcome.
Rationale for standardization
We wish to have roughly the same scale for different tag_outcomes. The current implementation takes the standard deviation across all foods for a specific tag (e.g. energy), then divide by this value. This is only ONE of the many ways to standardize for numerical stability.
Alternatively, it is also possible to multiply a fixed constant such as 1000 to ghge. The interpretation could be better. As long the original diet vector is intact (meaning that the ratio between the original food 1, food 2 are unchanged), one can artificially modify the coefficients as they wish.
However, it is important to keep consistency in the values and the inequality function!